10.07.2019 — v6.0. Обновление
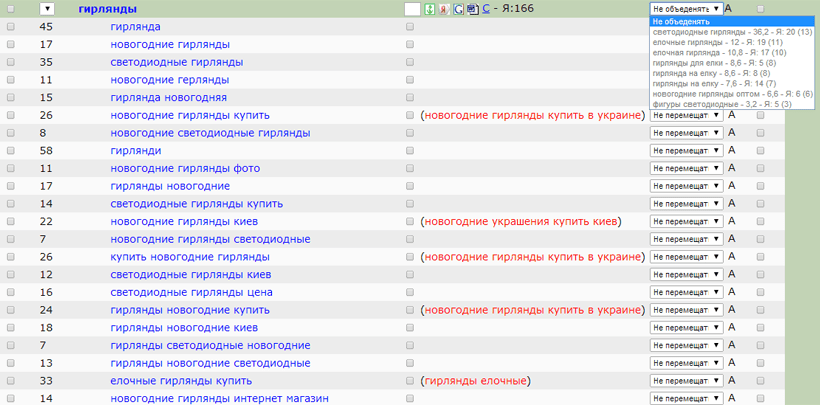
Разработали и внедрили модуль определения коммерческости по шкале от 0 до 1 + новый модуль «HandControl24»
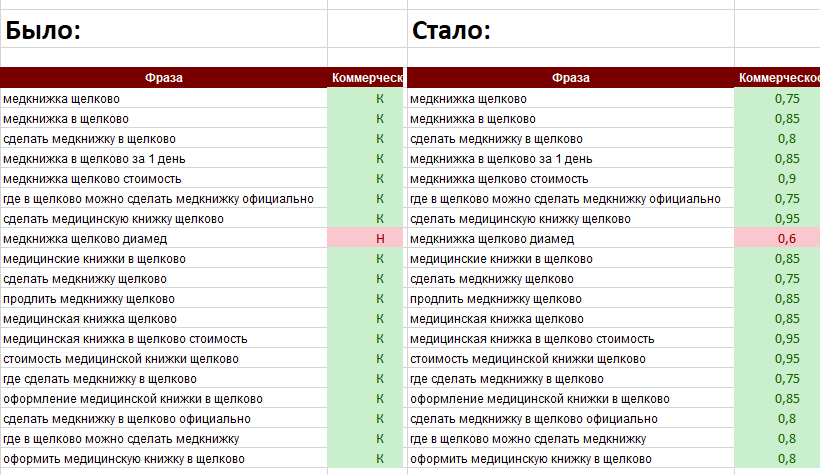
Разработали и внедрили модуль определения коммерческости по шкале от 0 до 1 + новый модуль «HandControl24»
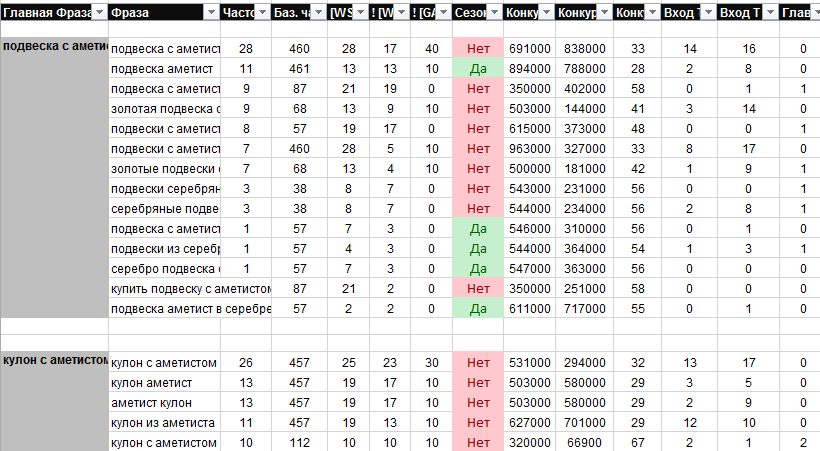
Полностью переписан и отлажен алгоритм группировки, как результат улучшилась точность и скорость группировки.Улучшено определение вида запроса. На вкладку «Структура» добавлена общая частотность «!» для всех запросов группы.
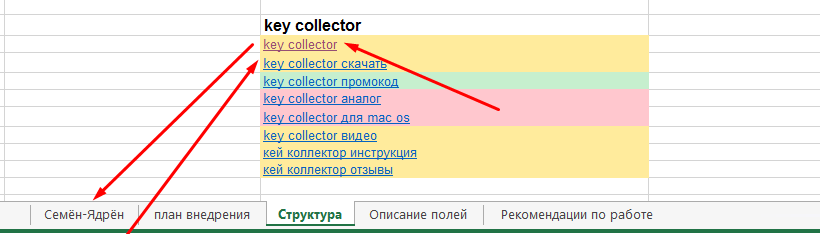
Добавлена выгрузка ссылок и доменов на внешние документы для группы запросов / всего ядра. В excel файл добавлено 2 новых вкладки: «Структура» и «Описание полей». В файл ядра вынесли ссылки на файлы ТЗ копирайтеру, что экономит массу времени на поиск нужного задания.
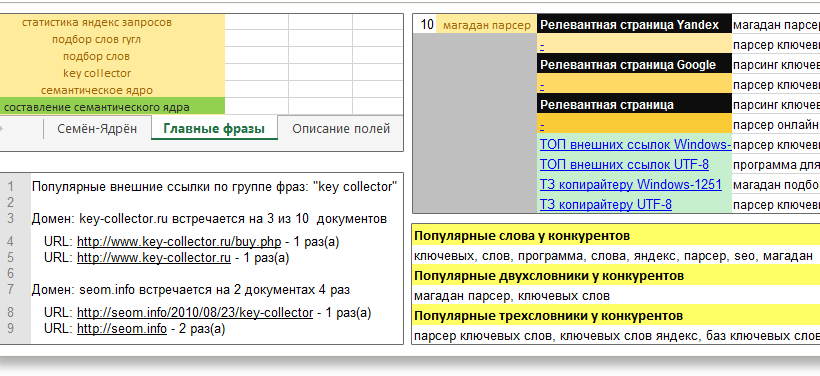
Полностью переработан поиск самых релевантных /видимых урлов/документов для группы фраз и соответственно расчет всех параметров для написания текстов. Добавили новый столбик с названиями ячеек:Наш Title, Наш Keywords, Наш Description, Наш H1, Наш H2.

Значительно переработан формат вывода ядра в xls формат.Разработана мощная система сбора и анализа конкурентов. В отчет добавлено большое количество новых параметров анализа конкурентов.
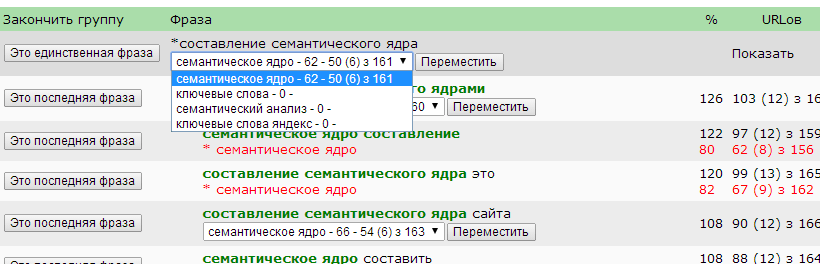
Скорость группировки увеличена в 30 раз. Улучшен интерфейс системы для работы семантиста. Добавлено отображение статистики группировки: сколько сгруппировалось, сколько осталось.
В кластеризатор добавлена возможность обработки фраз, которые уже сгруппировались. Добавлена авто проверка более подходящей группы для фразы.
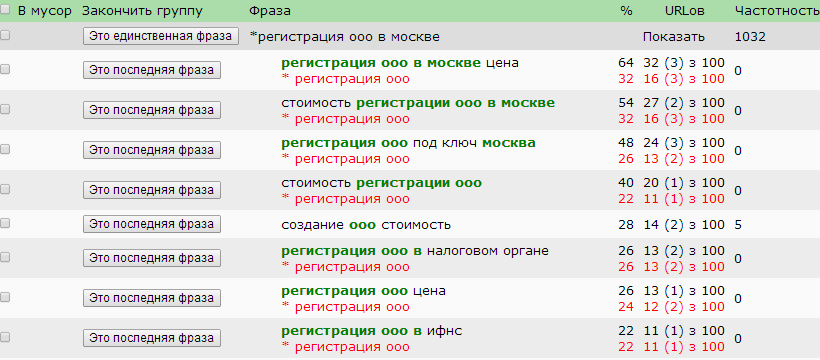
В кластеризаторе Семен Ядрен v.2.0 — полностью переработана идеология группировки семантического ядра с автоматической на полуавтоматическую.
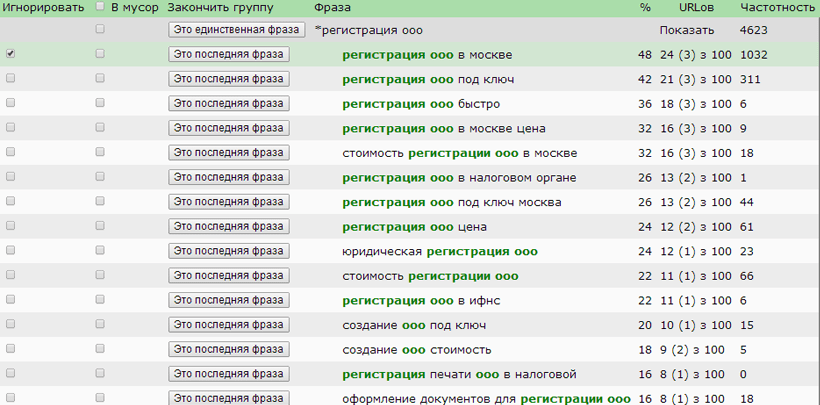
Первая система кластеризации проводила группировку семантического ядра только на основе поисковой выдачи, без возможности ручной корректировки.